October 14, 2019 – Industry Day: Workshops, Demos, Tutorials, and Tech Talks
Location: University of Kentucky, Gatton Student Center (GSC)
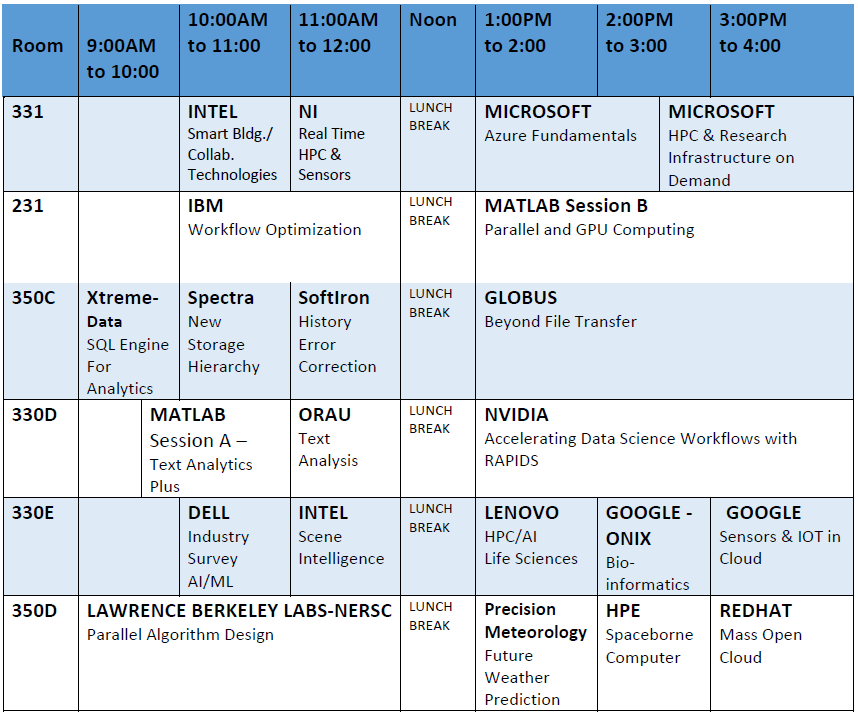
Rooms To Be Assigned (GSC: 231, 330AB, 330D, 330E, 331, 350C, 350D)
Workshop REGISTRATION – they are free but some will have limited seating.
Please note the Workshop/Tutorial Table below..... please register for those sessions of interest to you that do NOT overlap in time!
Register For Workshop Sessions
Workshop Agenda
1.
Jay Boisseau, Dell EMC AI & HPC Technology Strategist
Title: Technical Presentation: A Future Industry Survey for AI/ML
Abstract: The future of AI/ML hardware and software – there are lots of new accelerators just over the horizon for both training and inference. A survey of both hardware and software of what is coming in the world of AI/ML from across the industry, why it is significant and how it might impact data scientist’s future work. We are at the very beginning of the AI/ML journey that will give data scientists amazing new tools and capabilities.
Time: 1.5 Hours; Max Participants: No limit; Needs: Laptops
2. 

A. Adelaide Rhodes, Strategic Consultant, Health and Life Sciences Division - Onix, A Google Cloud Premier Partner
Title: Leveraging the Cloud to Support Data-Driven Discovery for Genomics
Abstract: This demonstration will take attendees on a journey from the familiar to the possible by deep-diving into some of the latest tools available in the Google Cloud stratosphere to support data-driven discovery for genomics. Starting with the basic building block of a Google Drive, users will find out how to augment their existing data mining practices by adding one or two new cool tools to their toolbox. For example, Google BigQuery now has the ability to interlink with Google Sheets directly, allowing users who are more familiar with the spreadsheet format to begin building data analytics functions in-house. Building on these fundamental applications available for data analysis, we will discuss how to get the most out of BigQuery for genomics applications such as biomarker discovery by running through a demonstration notebook containing code for a GWAS (Genome-Wide Association Study) analysis on a Google VM. Beyond simple machine learning we will also explore the potential of AI and Google high throughput data analysis capabilities, such as Tensor Processing Units and the Kubernetes platform for managing containerized workflows. This workshop is appropriate for advanced bioinformatics professionals as well as members of the scientific community who are interested in learning about the cloud in general. Come experience these exciting new possibilities in data analytics for genomics by attending this presentation, co-sponsored by Onix and Google.
Time: 1 hour; Max # Participants: No Limit; Special Needs: None.
B.
Gizmo Bentim, Cloud Customer Engineer, Google
Title: IOT & Sensors
Abstract:
The Internet of Things consists of devices exchanging information electronically. With the ever growing range of devices that allow for connectivity, problems arise with the complexity of managing such devices, securing their connections and gathering the data in real time. This demonstration will utilize the Google Cloud Platform to abstract these complexities, facilitate the deployment of services and fully manage the underlying infrastructure with intelligent design.
3. 
A. David Buchholz, Worldwide Director Unite - Intel
Title: Modern Collaboration in Next Generation Smart Buildings
Abstract:Come learn how the Intel Unite® solution can modernizes your next generation collaboration environment and integrate with Smart Building technologies. The Intel Unite® solution is an open architecture collaboration OS that integrates with a myriad of different technologies from unified communications and conferencing solutions to A/V control, and more. The solution can integrate with Smart Building strategy by enabling capabilities such as providing insight into room occupancy (people counting), privacy by automatically frosting smart glass during sessions and in the near future, environmental controls by polling participants on their comfort level.
Time: 1 hour; Max. Participants: 50; Special Needs: None
B.Craig Owen, Principal Engineer - Intel Corporation
Title: Scene Intelligence
Abstract:We are approaching a new tech inflection where our world is digitized and comprehended by machines enabled by rapidly maturing robotics, AI, IOT, client, and augmented reality capabilities. Intelligent spaces, or scenes, will consume data from many sensors and utilize AI to fuse and contextualize this data to build and comprehend 3D digital twins of spaces as they evolve in time: we call this Scene Intelligence. With a common framework for sensing, data processing, and compute components, Scene Intelligence utilizes temporal and spatial understanding to holistically contextualize data from many sensor modalities such as audio, vision, RealSense, LIDAR, RF, and environmental sensors, then applies compute, graphics, and AI to infer powerful scene understanding using technologies like OpenVINO and vision accelerators.
Time: 1 hour; Max. # Participants: No Limit; Special Needs: None
4. 
Robert (Bob) Spory, IBM, Cloud Technical Specialist,
Dan Thompson, IBM, Digital Business Automation Technical Specialist
Title: Workflow Optimization: Become a Process Modeling Ninja with Blueworks Live
Abstract: IBM® Blueworks Live™ is a business process modeling tool that lets you discover, map and document your processes. It is easy to use and accessible anywhere through a web browser. The cloud-based environment allows for effective collaboration in a way that is structured and usable by anyone at the University or within one’s company. The session will include an overview and hands-on tutorials to guide you through creating and editing a simple process model, allowing you to learn and perform business process modeling in minutes. Participants will use their own laptop to access a browser and participant in a hands on lab.
Time: 1.5 to 2 hours; Max Participants: 30; Needs: Laptops
5. 
Phong Le, Global Lead - HPC & AI Life Sciences Solutions, Lenovo
Title:Genomics at Scale: Designing a Genomics Data Center
Abstract: One of the greatest challenges in Life Sciences and particularly in genomics today is scale: scaling up in input data (from exomes, WES, to whole genomes, WGS), scaling up production (from a handful of genomes to tens of thousands), and the corresponding challenges they represent for the IT infrastructure. In this discussion, we will evaluate how genomics workflows differ from other HPC applications in terms of performance, bottlenecks, and usage of resources. Through a hands-on exercise we will size the production capabilities of a cluster and project the expected usage of compute and storage resources over time. Together, we will use such workload projections to develop a Bio-HPC usage plan, which has been proven to help Researchers, Developers, and their IT team plan workloads and better manage resources for large-scale genomics as well as any computational analyses of biological data. In addition, we will survey our combined experience to rank the current technologies with the most effect on genomics workflow acceleration. We will conclude this discussion by compiling a set of helpful strategies and tips to deploy Life Sciences HPC at scale.
Time: 1 Hour; Max. Participants: No Limit; Special Needs: None.
6. 
A.
Andy Hirsh, Customer Success Engineer; Nick Ide, Parallel Computing Product Manager - MathWorks
Title: Using MATLAB for Sentiment Analysis and Text Analytics
Abstract: Text data has become an important part of data analytics, thanks to advances in natural language processing that transform unstructured text into meaningful data. In this seminar, you will accompany an engineer on a journey to extract signals from social media noise by building a deep learning model in MATLAB to classify Tweets as positive or negative in sentiment. The exercise is adaptable to a wide range of applications, including informing trading strategies and processing customer survey data. Parallel computing concepts will be briefly introduced in the context of training and data pre-processing.
Time: 1.5 hours; Max. Participants: No Limit; Special Needs: None
B.
Andy Hirsh, Customer Success Engineer; Nick Ide, Parallel Computing Product Manager - MathWorks
Title: Parallel and GPU Computing with MATLAB
Abstract: This session will introduce parallel computing with MATLAB including GPU computing, topics include:
- Product Landscape
- Prerequisites and Setup
- Quick Success with parfor
- Deeper Insights into Using parfor
- Batch Processing
- Scaling to Clusters
- spmd - Parallel Code Beyond parfor
- Distributed Arrays; and 9. GPU Computing with MATLAB.
Time: 2-3 Hours; Max. Participants: 20: Special Needs: Bring your laptop for hands-on experience. You do not need to have MATLAB installed on your laptop or a GPU.
7.
A.Eric DeBord, Cloud Solution Architect - Microsoft
Title: Advanced HPC and Research Infrastructure on Demand with Azure
Abstract: During this session you will learn how Azure sets itself apart in the cloud by combining research focused compute platforms, specialized networking capabilities, and software offerings that enable bursting into the cloud seamlessly no matter where your storage is located. Additionally you’ll see firsthand how Microsoft software allows you to scale research workloads to thousands of cores, just in the moment you need them.
Time: 1.5 hours; Max. participants: No limit; Special Needs: None
B. David Ulloa, Cloud Solution Architect - Microsoft
Title: Azure Fundamentals
Abstract:Abstract: Microsoft Azure is an open, flexible, enterprise-grade cloud computing platform. It is an ever-expanding set of cloud services to help your organization meet your business challenges. Please attend this session to learn fundamentals services such as compute, storage, and networking. Learn about running hybrid scenarios leveraging platform services (PaaS) such as backup and disaster recovery.
Time: 1.5 hours; Max participants: No Limit; Special Needs: None
8. 
Igor Alvarado, Business Development Manager for Academic Research - National Instruments (NI)
Abstract and Bio: Read More
Title:Real-Time High-Performance Computing (RT-HPC) for Simulation and Control of Cyber-Physical Systems
Abstract: Traditionally, High-Performance Computing (HPC) systems have been designed to perform offline simulations under “flexible” time constraints and with no data streaming from/to sensors/actuators. In this work, we describe a new generation of Real-Time HPC (RT-HPC) systems that are capable of performing simulations in real-time within tight (strict) time constraints, in a deterministic manner and with extremely low jitter and latency. This type of systems can directly collect data from sensors, perform signal processing, classification/labeling and control tasks, and generate output signals in real-time. RT-HPC systems can also be used in hardware-in-the-loop (HIL) simulation applications, as well as in distributed, agent-based simulation systems where highly deterministic networks and clock distribution mechanisms can be used for synchronization purposes (e.g. time and frequency can be distributed over a fiber optic network within sub-nanosecond accuracy). For computation purposes, heterogeneous architectures that combine multi-core CPUs, GPUs and FPGAs are used. We will discuss how to leverage FPGAs for the implementation of task/application-specific processors and systolic arrays especially designed to perform specific mathematical and statistical functions. Also, FPGAs can have an important role on the implementation of adaptive computing strategies where processors are continuously optimized and adapted to the task at hand. These and other features are critical for simulating and controlling cyber-physical systems with thousands of nodes (agents) and hundreds of thousands of I/O signals from/to sensors and actuators, including but not limited to massive MIMO wireless communications systems for 5G and mmWave phased-array antennas, smart-grid monitoring and control systems, smart-transportation systems, swarms of drones and autonomous agents, etc.
Time: 1 hour; Max. Participants: unlimited; Special Needs: None
9.

Rebecca Hartman-Baker, Group Leader/Computational Scientist – NERSC/LBNL
Title: Parallel Algorithm Design
Abstract: In this session, we will discuss strategies for designing scalable parallel algorithms for high-performance computing. We begin with an overview of parallelization concepts and parallel computer architectures, followed by a discussion of the elements of parallel algorithms and strategies for designing parallel algorithms. In addition to discussion of concepts, we present real-life problems and solutions, and the implications of future architectures on parallel algorithm design.
Time: 3 Hours; Max. Participants: 40 seats
10. 
Zahra Ronaghi, NVIDIA,Senior Solutions Architect
Abstract and Bio: Read More
Title: Accelerating Data Science Workflows with RAPIDS
Abstract: The open source RAPIDS project allows data scientists to GPU-accelerate their data science and data analytics applications from beginning to end, creating possibilities for drastic performance gains and techniques not available through traditional CPU-only workflows. Learn how to GPU-accelerate your data science applications by:
- Utilizing key RAPIDS libraries like cuDF (GPU-enabled Pandas-like dataframes) and cuML (GPU-accelerated machine learning algorithms)
- Learning techniques and approaches to end-to-end data science, made possible by rapid iteration cycles created by GPU acceleration
Upon completion, you'll be able to refactor existing CPU-only data science workloads to run much faster on GPUs and write accelerated data science workflows.
Time: 2.5-3 Hours; Max. Participants: 50 seats; Special Needs: Laptops
11. 
Danny Scott, Data Warehouse Analyst - Oak Ridge Associated Universities
Title: Transfer Learning for Text Analysis
Abstract: The transfer learning technique is beneficial to machine learning modeling as potentially saves hundreds of hours of computation time. This tutorial will walk through applying transfer learning to publicly available models for text analysis. Keywords: Python, Jupyter, Tensorflow, Keras, Universal Sentence Encoder, Machine Learning, Text Analysis.
Time: 1 hour; Max. Participants: unlimited; Special Needs: none
12. 

Michael Daitzman, Director Engineering and Product - Mass Open Cloud. (Sponsored by Red Hat)
Title: Elastic Secure Infrastructure - Malleable Hardware to Meet HPC and Cloud Compute Demand Surges
Abstract: As paper and project deadlines approach both HPC clusters and Cloud testbeds become 100% utilized. Elastic Secure Infrastructure, developed at the Mass Open Cloud, is being integrated with Cloud Labs and HPC clusters. This integration will make resources available as needed by both the HPC and cloud research communities. By affiliating with institutional clusters, this effort will integrate hundreds of thousands of compute cores and enable systems researchers (not just application researchers) to be the beneficiaries of institutional funding. Through the inclusion of non-NSF-funded resources, these resources will become available for use both by industry and by members of the open-source community. Also, this approach creates a much larger community to enhance and maintain the underlying infrastructure. We plan to assist other groups in replicating these capabilities. This will enable the Open Cloud Lab to share institutional resources (e.g., HPC clusters) at these new locations as well as at any sites that choose to stand up Open Clouds like the Mass Open Cloud.
Time: 1 hour; Max # Participants: No Limit; Special Needs: None.
13. 
Bob Wassell, Solutions Architect - Softiron
Title: When Bits don't Byte: History of Error Correction
Abstract: The history of error correction and detection and how it led to Ceph’s Erasure Coding Techniques - 70 years of academic innovation in the development of error correction codes have led to the advanced erasure coding techniques that we use in Ceph. Learn more about how these came about, the different types, how they work, and how we use them in distributed storage today. Erasure Coding is the latest in a long line of error detection and correction approaches over the last 70 years which have all had an impact on the way we approach storing and recovering data in sensible and efficient ways. An overview of the main approaches over the years, including the parity bit, the hamming codes, reed-solomon, and how they have impacted media storage, RAID, and distributed storage. An overview of erasure coding across distributed storage and specifically Ceph, the different erasure coding plugins available, how they compare to other distributed storage projects, the pros and cons vs triple replication, the performance payoff, and also talk about what SoftIron is doing in this space.
Time: 1 hour; Max. Participants: No Limit; Special Needs: None.
14. 
David Feller, VP of Product Management and Solutions Engineering - Spectra Logic
Abstract and Bio: Read More
Title: Updating the Outdated Storage Paradigm to Handle Complex Computational Workloads
Abstract: Accelerating discovery in computational science and high performance computing environments requires compute, network and storage to keep pace with technological innovations. Within a single organization, interdepartmental and multi-site sharing of assets has become more and more crucial to success. Furthermore, as the growth of data is constantly expanding, storage workflows are exceeding the capabilities of the traditional file system. For most organizations, facing the challenge of managing terabytes, petabytes and even exabytes of archive data for the first time can force the redesign of their entire storage strategy and infrastructure. Increasing scale, level of collaboration and diversity of workflows are driving users toward a new model for data storage. Join us for a deeper look into storage system options and the nuances of a two-tier system and data management between them. We will cover storage management software options; cloud vs. on-premise decisions; and using object storage to expand data access and create a highly effective storage architecture to break through data life cycle management barriers.
Time: 1 Hour; Max. Participants: No Limit; Special Needs: None.
15. 
Lee Liming, Technical Communications Manager - Globus, University of Chicago
Title: Globus - Beyond File Transfer
Abstract: Organizations need fast, secure, and reliable data management solutions as they architect infrastructures to address the oncoming demands of HPC's convergence with AI and data analytics -- and researchers also need them as they collaborate on data-intensive projects every single day. Globus has spent the past nine years developing a research data management service now used by over 100,000 users at thousands of organizations worldwide. In this session, we will demonstrate Globus capabilities from two perspectives: end-user/researcher and system administrator. We will begin by introducing the many features of the Globus web application and command line interface, as well as the capabilities that let users go beyond simple file transfer. You will learn how to share data with collaborators and set up personal endpoints. Next, we'll show how Globus supports management of Protected Health Information (PHI) including data regulated by the Health Insurance Portability and Accountability Act (HIPAA), Personally Identifiable Information (PII), and Controlled Unclassified Information (CUI). With higher assurance levels for managing restricted data, researchers can easily work with this data and share it securely and appropriately with collaborators, while meeting compliance requirements. Finally, we will provide a detailed walk-through of installing and configuring a Globus endpoint, including deployment configurations such as multi-server data transfer nodes, using the management console with pause/resume rules, and integrating identity systems for streamlined user authentication. We will also discuss Globus connectors for storage systems such as Amazon S3, Ceph, HPSS, Google Drive, and Box.
Time: 3 hours; Max. # Participants: No limit; Special Needs: None
16. 
Suzanne Smith, Professor, Department of Mechanical Engineering - University of Kentucky
Title: Precision Meteorology: The Future of Unmanned Aircraft Systems (UAS) for Weather Forecasting
Abstract:Accurate weather forecasts enable substantial financial returns across sectors including transportation, agriculture, and energy, and also increase safety and reduce economic losses from high-impact weather. Evaluation of economic sensitivity to weather by state and industry sectors reinforces the cost-benefit value of the U.S. weather forecasting infrastructure. Global Numerical Weather Prediction (NWP) accuracy and lead time steadily improved over 30 years through interconnected advancement of atmospheric process representation, model initialization, ensemble forecasting, and high-performance computing. However, practical scientific and technology limits are being reached, dictating that new paradigms are needed to achieve accurate forecasts of key atmospheric processes at sub-1km scales to meet the need established for sector microscale weather forecasts for efficiency, safety and resilience. Simultaneously, societal changes (including population and associated municipal growth), the increased number of $1B weather events, and the emergence of data-science driven weather forecasting are motivating change of the weather enterprise. The state of current numerical weather prediction and current in situ and remote data observing assets enable accurate forecasting of large-scale weather events such as fronts and lake-effect snows, but do not enable accurate forecasting of local-scale phenomena which depend on complex surface interactions or boundary layer dynamics. For the first time in history, UAS technologies make it possible to overcome atmospheric boundary layer undersampling, the primary barrier to accurate local-scale meteorology, by enabling on-demand, in situ measurements of critical, complex atmospheric characteristics at precise locations and times. This presentation includes an overview of current models and data sources for weather forecasting, describes envisioned future applications, and presents the local-scale gaps that can be addressed with UAS observations to enable precision meteorology.
Time: 1 hour; Max. # of Participants: No Limit; Special Needs: None.
17. 

Mark R. Fernandez, Americas HPC Technology Officer & Spaceborne
Computer Payload Developer - HPE
Title: Spaceborne Computer: The Dawn of HPC and AI Above the Clouds
Abstract:Having successfully completed its 1-year mission aboard the
ISS, Spaceborne Computer has proven that state-of-the-art
supercomputing systems can operate autonomously in the harsh
environment of space and can accompany space explorers as humanity
extends its reach beyond Earth. The trials and tribulations
encountered and overcome by Spaceborne-I will be reviewed. Plans for
Spaceborne-II will be presented, including the inclusion of a GPU for
AI/ML workloads. Since self-sufficient computer systems enable
self-sufficient space explorers, the potential use of AI to improve
the autonomous operation of the system is a key component of the
experiment. Potential use in Earthly edge and other applications will
also be discussed.
Time: 1 hour; Max. # Participants: No limit; Special Needs: None.
18. 
Ravi Chandran, Cofounder/CTO; Jay Desai, Cofounder/SVP - XtremeData
Title: SQL Engine for Analytics at Scale (free for academic research)
Abstract:This workshop will feature a demonstration that will empower attendees to tackle complex analytics on terabytes of data with ease and simplicity. The demonstration will be on one of the major clouds (AWS, Azure, GCP and IBM (including Z/Linux) and will show the entire data pipeline from start to finish: spinning up a cluster, ingesting raw data, running complex SQL, scaling-up, scaling-out and shutting down when idle. XtremeData's SQL engine has been architected from the ground up for scale, speed and simplicity. All three of these factors will be showcased and described. Other solutions in the market may also claim one or two factors (scale or scale & speed), but none can claim all three. In particular: scale by definition implies a distributed, parallel system, which then typically implies complexity of configuration and performance tuning. All distributed (MPP) SQL engines in the market today address this complexity by imposing certain constraints on data organization and data placement. Two common examples are requiring tables to be stored in sorted order and requiring tables to be hash-distributed (or locally clustered) on the Join key. These constraints are very expensive to the end-user, both in terms of time and money. In this workshop we will explain why, and what we have implemented internally in our engine to eliminate these constraints. Attendees will experience a new-generation analytic engine that radically simplifies analytics at scale.
Time: 1 hour; Max. # Participants: No Limit; Special Requirements: None.







































